
Data is the most valuable treasure when developing functions for autonomous driving. Patrik Moravek, responsible for Data-Driven Development at dSPACE, explains how this treasure can be harnessed as efficiently as possible.
Patrik, what is data-driven development?
Generally speaking, data-driven development is a software development approach. It is an answer to a new era in software development that includes artificial intelligence (AI) based algorithms, more specifically a subclass of AI called machine learning. This new development approach makes development easier, faster, and more efficient because it addresses the new aspects and challenges of development of AI-based functions.
In the automotive sector, the development of ADAS and AD functions relies on machine-learning models that analyze the complex situation surrounding the vehicle. To develop and configure these models, sample sensor data from real world is necessary – a lot of sample data. The amount of sample data is so huge that actually the preparation of this data takes up most of the time (and resources) during development. Consequently, if the resource allocation within the development process has shifted, the focus of the development optimization has to shift as well. If more money is spent on the preparation of data than on writing a code, the preparation of the data shall become a focus of cost optimization. This shift of focus is addressed by the data-driven development approach.
To a certain extent, this can be compared to model-based development. Introducing models and simulation in software development led to significant acceleration of the development, especially in the control domain. It reduced the complexity and broke down the development into more easily handled steps, and therefore, saved resources and made projects more manageable. Similarly, data-driven development includes specific processes, methods, and tools that make development of AI-based functions more efficient and faster.
What is data-driven development good for?
Development of new functions in modern vehicles such as lane keeping assistants (LKA), traffic jam assistants (TJA), and a higher level of autonomous driving is based on perception ability which is implemented with machine-learning models. To mature this perception ability and make it reliable in the real world, many examples from the real world have to be collected in advance and used in the development and validation. One can say that the more distinct examples are available for the development, the more reliable the software works in operation (on the road). At certain moments in the development, no more programming is done; only the data itself improves the reliability and performance.
Therefore, one of the goals of development is to collect as many relevant (and distinct) examples of traffic situations as possible, to build a robust training and validation data set to avoid software failures on the road. Data defines AI performance and AI allows autonomous driving.
A knife is great for cutting off a twig but it is not very suitable for cutting down a tree. Similarly, tools working well with megabytes and gigabytes of data do not fit well for larger volumes in terabytes and petabytes.

What are the challenges in data-driven development?
The main challenge is the volume of data in the process. Data collection and road testing cover hundreds of thousands or even millions of kilometers on the road. In terms of collected data, we are talking about petabytes or hundreds of petabytes of data.
The large storage size and the associated costs are not the only implications from having to collect such high volumes of data. Another implication is the need for appropriate processes and tools working with this data that were not available on the market before this need emerged.
Imagine that you need a cutting tool. A knife is great for cutting off a twig but it is not very suitable for cutting down a tree. Similarly, tools that work well with megabytes and gigabytes of data do not fit well for larger volumes such as terabytes and petabytes.
It is a fact that not all the data collected on the road has the same value in development and validation. Actually, various sources claim that about 90-95% of the data collected is useless. The challenge is to distinguish between usable and unusable data. Therefore, one focus of data-driven development is to collect, store, and use the road data that really provides value in development and validation and gets rid of worthless data.

What is the solution from dSPACE?
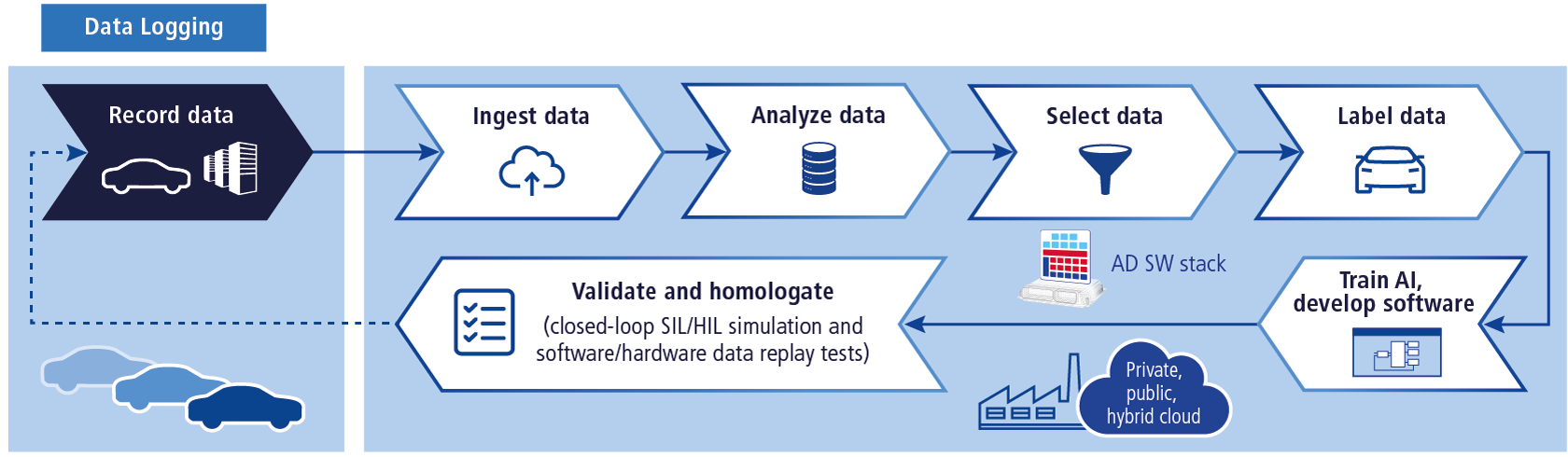
dSPACE as a partner in simulation and validation has identified the challenges in the early phase and built appropriate tools that help our customers to improve the processes in data-driven development. Our offer covers the entire path of data from data recording to data replay (aka reprocessing). Moreover, it smoothly extends to closed-loop simulation validating ADAS/AD functions in a fully virtual world.
- Starting with data logging, dSPACE provides smart solutions to record all the data or run an onboard analysis and optimize the data recording. Manual tagging with RTag or AI-based filters extend the capabilities of AUTERA data logger and RTMaps logging software to capture only the relevant situations and reduce the data amount.
- High-speed data ingest with our Upload station ensures that the data gets to the developers and test engineers without unnecessary delays.
- For an effective use of collected data, IVS, the Sensor Data Management Platform for automated driving from Intempora (a dSPACE company) provides access, visualization, annotation, and data selection.
- Validation of functions and systems is possible only against measured reference information (aka ground truth). In the context of the development of autonomous driving functions, the reference is based on annotation of data from sensors representing the truth information. Here, understand.ai, a dSPACE company that focuses on large scale and automated annotation, plays a crucial role.
- Validation with recorded and annotated data is conducted with our data replay systems. Here, we provide tools and solutions for validation of algorithms as well as complete systems including both hardware and software. Data replay systems are composed of our established products such as RTMaps, VEOS, SCALEXIO, and ESI Unit depending on the customer-addressed use case.
Beyond that, we see specific customer use cases: validation with recorded data, called open-loop testing, is not the only way to leverage the data. High-quality data is also used to improve the training data set. In addition, recorded data plays an important role in transition to closed-loop validation. First, IVS with its plug-ins allows automated analysis of traffic situations, and thus, provides better understanding of related traffic parameters. Second, dSPACE offers generation of synthetic scenarios from collected data applicable in closed-loop simulations, which improves planning and execution of the overall validation strategy on the way to homologation.
Advantages of dSPACE Solutions for Data-Driven Development
- AI algorithms on AUTERA allow data to be reduced as it is logged, and before cloud storage costs are incurred.
- IVS enables the analysis and preview of data brought in from different regions of the world and stored in globally distributed data centers without the need to copy the actual sensor data to a central location.
- Jobs in IVS are based on a highly optimized runtime engine that saves computing time.
- Automated and AI-based scenario detectors and annotation options contribute significantly to time and cost savings in data analysis.
- The data replay solutions are performance-optimized for e.g., hybrid architectures like at Microsoft Azure and Equinix.
Who are the partners onboard?
A broad partner ecosystem in development of ADAS/AD functions is a must. It is a crucial aspect to facilitate our customers’ tasks. The entire story and solution for end-to-end data-driven development is complex and crosses several expert domains. It is not in the hands of one company. To solve customers’ problems in their entire complexity, we cooperate closely with many partners addressing different areas. For example, in data logging and replay, close cooperation with sensor providers (e.g., Velodyne, LeddarTech, Robosense, LeopardImaging, and Sensing World), image chip providers (e.g., OnSemi, NXP), or ECU providers (e.g., Nvidia, Renesas) helps to commission the system in a short time. Obviously, this increases customer satisfaction as the demanding coordination among suppliers is reduced. Computing infrastructure is another area where partnership with companies such as AWS, DELL, IBM, Microsoft, SVA, and others makes our systems easily deployable to various environments and allows them to run with maximal efficiency on utilized resources. Connecting software, hardware, and data in different locations is often efficiently feasible only with the support of collocation centers offering premium network connectivity. Here, for example, we work with Equinix.
Further, we cooperate a lot with engineering companies that flexibly extend our capacity on engineering tasks as in-vehicle integration or managed services, including system integration and operation.
The partner ecosystem is really rich and dense, and I am happy that all partners are so motivated to work with dSPACE to address various customer needs.
What is the benefit for the customers?
Our tools and solutions improve the data-driven development process for our customers, so they work more efficiently achieving their goals faster and eventually also for lower total costs. This is the feedback we receive from our customers and we build on it further.
The comprehensiveness and consistency of our solutions save the customer significant time and cost for the integration, which, to a large extent, is already delivered with our solution. The partner ecosystem multiplies this aspect even further. The more that is delivered from one source or an ecosystem of partners, the less integration effort and risk remains for customers.
We always think about modularity and scalability. We offer our customers gradual growth of the data-driven development tooling with the growing scale of the projects. Customers can start small and later build on previous investments.
Our tools are reusable. That is the case among various projects but a big benefit for our customers is the reusability of our products in different applications too. Let’s consider hardware-in-the-loop (HIL) products. They are an inherent part of data replay in the hardware setup, meaning that customers who own dSPACE HIL systems can save significant costs when adapting these to data replay test stations.

What is the future and how will dSPACE further develop its offer?
Our goal is clear – maximize efficiency of the data-driven development process for our customers. If our customers save money and time using our tools on the way to provide safe autonomous driving, it’s a win-win situation. This is our understanding of partnership.
Optimization and improvement along the data pipeline come with better data insight – understanding the content of the data and its value in successive steps. If one can already decide during data recording which data is worthless, this is a direct cost saving. On the other side, being able to understand the value of the data is not free-of-charge and it is eventually a trade-off between investment in data insight and cost saving along the data pipeline. And that is what we address.
AI plays a central part in data understanding (such as scenario detection in recorded data), and therefore, we invest a lot in the topic. We already employ AI algorithms in our tools and are working on further enhancements. AI enhances our product in data logging, annotation, and in data management, for example. We have our own data collection strategy based on the dSPACE collection platform aka sensor vehicle to address exactly the use cases that serve the tool improvement.
Thank you for the interview.
dSPACE MAGAZINE, PUBLISHED JUNE 2022



