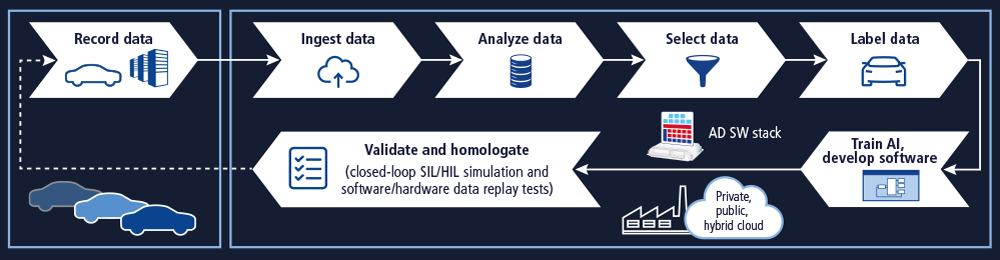
An optimal data-driven development solution consists of a fully integrated pipeline for the continuous development of the machine-learning-based functions needed for autonomous driving. However, there is a multitude of bottlenecks awaiting in the development process, such as inconsistencies in formats and interfaces, which are a common source of project delays. dSPACE ensures that you successfully master your data pipeline challenges with the right technologies, methods, and outstanding expertise.
The reliable operation of an autonomous vehicle is a highly complex task due to the endless complexity of the real world and the corresponding vehicle environment. Traditional problem-solving approaches, such as simple logic comparisons in the form of “if-then-else”, are not sufficient. The number of conditions is countless. A completely different approach had to be adopted by developers to tackle these complex issues. This approach focuses on the implementation of automated parameterization of a general model with the help of example use cases, rather than solving the problem with the highest accuracy and completeness through manually written code. The more data is fed in, which is often described as training, the closer the parameterization result will get to the expected result, and the safer the vehicle becomes. This is a relatively efficient way to prepare an autonomous vehicle for reality without having to define its complete “universe” in code beforehand – which would be impossible. Therefore, the development process is called data-driven, or data-centric instead of code-centric. For development, this means that we have to adapt the processes to the data instead of routing the data though the existing process. Thus, the data, the data pipeline, and the accompanying tools become the center of the development process.

Advanced Data Logging in the Vehicle
The starting point of the data pipeline is the vehicle. It collects all the data which is then used in the process. At the vehicle level, the data sources are all sensors, buses, and networks that transmit information from internal vehicle sensors and ECUs. The vehicle and the data collection system are also the first place where much can be done to optimize the data pipeline. First, the in-vehicle infrastructure and architecture of the logger itself must support data transmission from I/O interfaces to data storage as fast as possible and without data losses. Second, not all of the recorded data will be needed. Only a smaller part of the data is really valuable and will have impact. So why not dismiss the superfluous data at a very early stage in order to save storage and time? Alternatively, only the valuable data is recorded and stored while the superfluous data is dumped. This means that we need a technically powerful and flexible data logging system, and also functions between recording and storage that ensure that only the right data is stored. This is where the dSPACE solution for smart data logging comes into play. It consists of data logging hardware and software, data ingestion and management software, and accompanying services. A central component of this solution is the AUTERA product family, which is tailored for data logging in demanding ADAS/AD applications. It can be combined with RTMaps, a lightweight but powerful development and logging software, and with RTag, a mobile tagging application. dSPACE also has the technology and know-how to filter and reduce recorded data volumes to a relevant subset. Our artificial intelligence experts will be happy to help. If desired, dSPACE and its partners can also assist you with a dedicated vehicle equipment and data acquisition service.
Data Ingestion – Making Data Available to the Developers
The data ingestion pipeline is a part of the data pipeline which ensures that the data flows from the vehicle to the software and test engineers quickly and in the right quality. This is the second stage in the data pipeline where we will increase efficiency and quality. Even if the data has already been intelligently filtered during recording, there is usually still room for data reduction. Camera data, for example, is particularly memory-consuming. Data can be reduced further by using more computational power and non-real-time processing. This can be done outside the vehicle, where more energy is available. If the data has not been filtered before in the vehicle, there is even more to do in the ingestion step to reduce the data volume. Efficiency can only be improved if all data that is not needed, or that is corrupted or incomplete, is simply not ingested. The data would only take up space without any added benefit. If this quality check is not performed in the vehicle, the ingestion pipeline is another pipeline stage where it can be implemented to minimize the required storage, thereby saving costs. Quality control includes, among others, format checks, error checks, and consistency checks. Further reduction of data can be achieved by understanding the content of the data. Therefore, processing of the data and extracting certain metainformation takes place in the ingestion pipeline as well. It not only allows filtering and data reduction, but it also improves search and data organization. The generation of map and sensor previews allows for visualization and speeds up responsiveness in data access. Previews can be automatically anonymized to also comply with GDPR regulations. dSPACE offers a comprehensive solution for data ingestion. The high-bandwidth AUTERA Upload Station with its hot-swappable AUTERA SSDs ensures a speedy data upload. IVS from Intempora integrates native transmission protocols and the framework for plugging-in customized processing modules for data ingestion steps. By default, quality checks, redundancy reduction, preview generations, and tagging modules are included. The annotation services offered by understand.ai, a dSPACE group company, helps you label selected data rapidly and with the highest quality, even for very large data volumes. And finally, the UAI Anonymizer as an identity protection anonymizer removes more than 99% of all identifiable faces and license plates, and it is GDPR-, APPI-, CSL-, and CCPA-compliant by design.
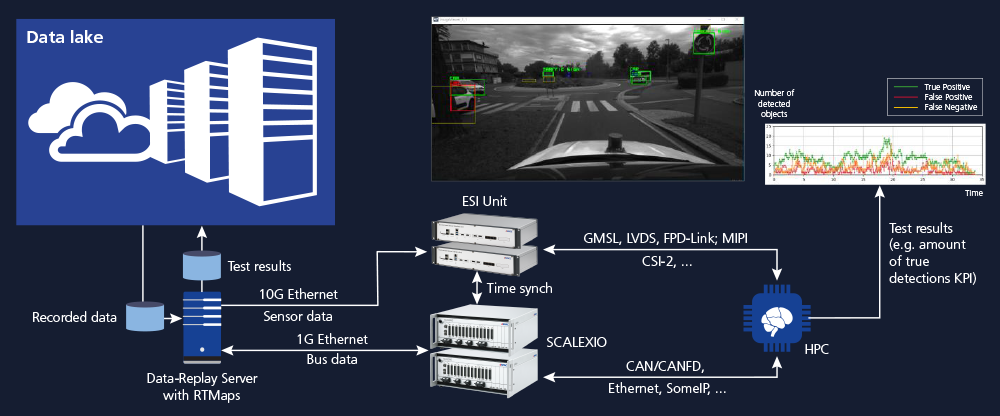
Testing: Safety First
Autonomous vehicles must function properly in all imaginable and unimaginable traffic situations. Automated testing plays a particularly important role, as only a fully tested vehicle and vehicle software can be trusted on the road. There is a wide range of test methods applicable depending on the development stage. dSPACE products provide solutions to integrate and apply these methods smoothly into the overall testing and homologation process for each platform and new vehicle model. Data replay testing (a.k.a. reprocessing), which means replaying recorded sensor and bus data to a system under test and evaluating its output against ground truth data, has established itself as a key test and validation methodology in ADAS/AD. Such a testing methodology provides an efficient and cost-effective way to analyze the behavior of autonomous vehicles with data from real driving situations, which is the key for full safety assessment of the vehicle. Data access and its synchronous streaming are crucial aspects for data replay, which makes it a main part of the data-driven development pipeline. The methodology can be applied as a pure software (SW) data replay test early in the development process, or as a hardware (HW) data replay test later in the process after system integration. Software data replay usually does not operate under real-time constraints and can run faster than real time to facilitate quick accuracy checks. Moreover, it can be performed long before a hardware prototype is available. Hardware data replay on the other hand involves deploying a central computer or sensor ECU, which is connected to the test system and is fed with recorded synthetic or real data. This makes it possible to test the hardware, the electrical interfaces, as well as the software in the conditions closest to on-road testing. Data replay tests can be further enhanced by inserting failures and manipulating the data streams. More and more, cloud services are used for data replay testing. dSPACE and its partners offer outstanding solutions for data replay tests based on public cloud, on-premise and hybrid cloud infrastructures. The dSPACE data replay portfolio includes a multitude of tools to best fit your needs, including SCALEXIO, the modular real-time system for accurate bus and network interfaces; the Environment Sensor Interface (ESI) unit, the powerful FPGA board for sensor interfaces; VEOS, the offline simulator for early-phase (virtual) ECU simulations; and RTMaps, the state-of-the-art data parsing and streaming software. In addition, there is IVS, the data management software for easy accessibility to the recorded datasets of interest. All of these tools are integrated to provide fully automated test solutions that let you perform continuous 24/7 tests against thousands of driven and synthetic kilometers.

The dSPACE AUTERA hardware lets you meet even highest data acquisition demands. As powerful yet easy-to-use data logging software, RTMaps offers flexible configuration options.

Data Augmentation
A challenge is not only to prepare autonomous vehicles for situations that were already covered in previously recorded data, but also to confront them with completely new and unknown scenarios for which there is no real data at all. This is especially important for testing corner cases, which are impossible or too risky to test in reality. Artificially created data from sensor-realistic simulations is used to extend a test data set. The traffic scenarios and environment can be created from scratch or by synthesizing a real traffic situation and manipulating its parameters. A second method to extend the test data set is to use recorded data and manipulate it in a way which adds synthetic traffic participants with realistic behavior to the situation. dSPACE products already support the manipulation of real scenarios, especially the solution for scenario generation developed by dSPACE and understand.ai. The solution lets you transfer recordings from real test drives to the simulation and perform thousands of tests of safety-critical and realistic driving scenarios with dedicated hardware and software conveniently as a simulation. These scenarios can be changed and extended artificially, which is very useful in scenario-based testing where a great number of scenarios have to be executed. The dSPACE solution for sensor-realistic simulation, AURELION, is a new, powerful tool not only for cloning but for manipulating reality in simulation. dSPACE also provides methods for generating artificial training data that will dramatically decrease development costs.
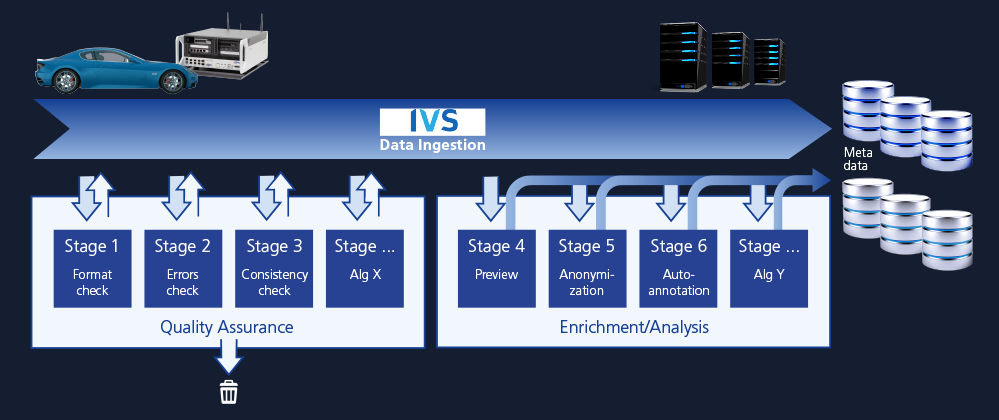
The data ingestion pipeline makes sure that high-quality, enriched, and – optionally – anonymized data reaches the developers.
Seamlessly Integrated
As shown above, dSPACE, its group companies, and partners support the entire data pipeline with seamlessly integrated tools, ensuring a smooth data flow. With dSPACE tools and dSPACE expertise, you can keep your data pipeline running even during critical phases of your development projects.